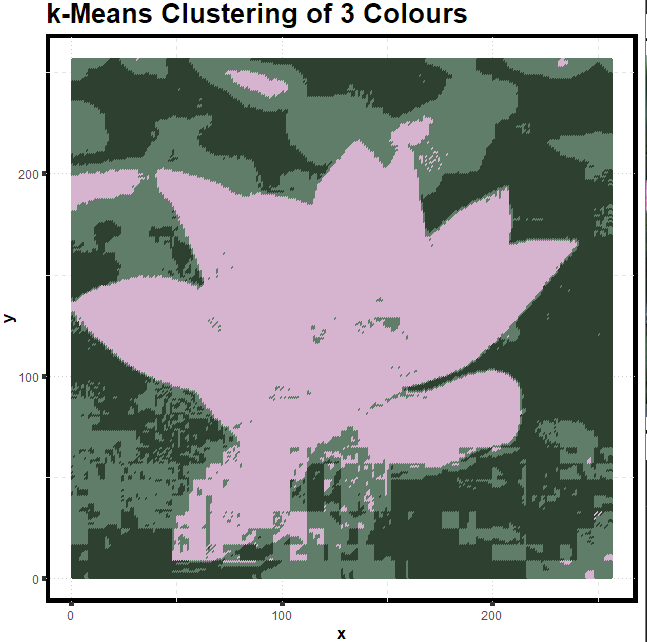
description: cluster colors in a flower image through k-means
downloading and reading image file
1 | library("jpeg") |
processing image data
1 | imgDm <- dim(img) |
set a theme for drawing the image
1 | library(ggplot2) |
image clustering using K-means clustering
1 | kClusters <- 3 |

outcome